

DatamedIQ – wie es der Name ja schon anklingen lässt, sind Daten das Herzstück unserer Arbeit. Ununterbrochen fließen von unseren Online-Apotheken verschiedenste Transaktionsdaten bei uns ein. So erhalten wir tagtäglich riesige Datensätze, gespeist mit unterschiedlichsten Informationen, beispielsweise wie alt die Shopper im Apotheken-Versandhandel sind, wo sie wohnen, ob sie männlich oder weiblich sind und natürlich welche Produkte sie kaufen. Wie wir aus Big Data mithilfe von künstlicher Intelligenz Hochrechnungen modellieren, die 100 % des deutschen Apothekenversandhandels abbilden, erfahren Sie, wenn Sie weiterlesen.
Für ein gemeinsames Verständnis des Begriffs Big Data und was sich dahinter verbirgt, lohnt es sich, die typischen Merkmale von Big Data anzuschauen, die sogenannten 6 V´s:
1. Volume besagt, dass sich Big Data anhand hoher Datenmengen definiert.
2. Variety meint Daten aus unterschiedlichen Quellen in unterschiedlichen Formaten, also die Vielfalt der Datentypen & -quellen.
3. Velocity bezieht sich zum einen auf die Geschwindigkeit, in der neue Daten generiert, und zum anderen auf die Geschwindigkeit, in der diese verarbeitet werden.
4. Validity – manchmal auch als Veracity bezeichnet – beschreibt die Qualität der Daten, wobei insbesondere die Glaubwürdigkeit der Quelle eine entscheidende Rolle spielt.
5. Value bezeichnet wiederum den (Mehr-)Wert der Daten für das Unternehmen. Daten werden erst dann zu Big Data, wenn die enthaltenen Informationen einen konkreten Einsatzzweck erfüllen.
6. Variability bezieht sich auf die Variabilität der Datenstruktur, teilweise aber auch auf Fluktuationen innerhalb der Daten z.B. bei Saisonalitäten.
Diese sechs Attribute müssen Daten mit sich bringen, um als Big Data definiert zu werden. Die Daten, die bei DatamedIQ in die Hochrechnungen fließen, erfüllen alle 6 V´s.
KI, ein weiterer Begriff, der medial seit einigen Jahren oft zum Einsatz kommt, ist die Abkürzung für künstliche Intelligenz. Man versteht KI als Oberbegriff für die Simulation menschlicher Intelligenz mithilfe von Maschinen. Bei aller Aktualität ist der Begriff aber tatsächlich nichts Neues. Im Englischen als „AI“ (Artificial Intelligence) bezeichnet, wird meist die Dartmouth Conference im Jahr 1956 als Geburtsstunde angeben. Die Forscher John McCarthy, Marvin Minsky, Nathaniel Rochester und Claude Shannon beantragten bei der Rockefeller Foundation Forschungsgelder für eine Studie. Anhand dieser wollten die Forscher den Beweis erbringen, dass jeder Aspekt des Lernens und der menschlichen Intelligenz mit Hilfe von Maschinen beschrieben und simuliert werden kann. Das war seinerzeit wegen der schwachen Rechenleistung von Maschinen äußerst problematisch, wie man sich denken kann. Heutzutage wächst nicht nur die Menge an digitalisierten Daten täglich an, sondern auch die verfügbare Rechenleistung, die es ermöglicht, diese zu prozessieren.
Ein Teilgebiet von künstlicher Intelligenz ist das sogenannte Machine Learning. Mithilfe von mathematischen Algorithmen ermöglicht man es Maschinen, selbstständig Wissen aus Erfahrung zu generieren, Muster in den Daten zu erkennen und Vorhersagen zu treffen. Klassische Anwendungsgebiete sind beispielsweise Wettervorhersagen oder Filmvorschläge auf Basis der angegebenen Präferenzen. Wichtig zu wissen: dabei sind Maschinen nicht komplett autonom. Man benötigt immer noch den Menschen, den Programmierer, der konstant Anpassungen vornimmt, um das Output zu optimieren.
Deep Learning geht noch einen Schritt weiter. Im Rahmen dieses Teilgebietes der KI werden neuronale Netze verwendet, mit denen sich die Maschine selbst in die Lage versetzt, Strukturen zu erkennen und die gewonnenen Erkenntnisse zu evaluieren. Beispiele für Deep Learning ist das autonome Fahren oder auch die Sprach– und Gesichtserkennung bei mobilen Devices.
Machine Learning ist ein fortlaufender Prozess, dessen Ergebnisse mit steigender Datenmenge konstant verbessert werden. Je mehr Daten in das System fließen, umso besser das Output. Der Mensch wird aber nicht obsolet. Programme müssen weiterhin geschrieben werden, mit deren Hilfe eine fertige Lösung erstellt werden kann.
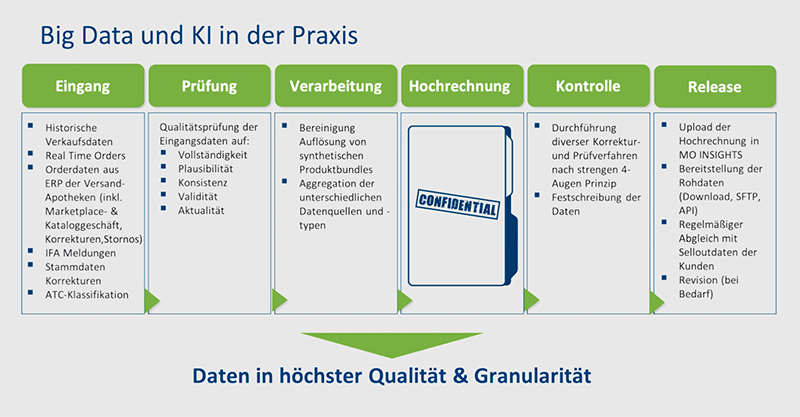
Bei DatamedIQ beginnt alles mit Big Data, die wir aus unterschiedlichen Datenquellen geliefert bekommen. Zum einen sind das historische Verkaufszahlen, aber auch tagtäglich die Daten der Bestellung bei Versandapotheken. Zudem beziehen wir Stammdaten von der IFA und teilweise auch von unseren Bestandskunden. Darüber hinaus beziehen wir statistische Daten für Tools wie den Persona Explorer. Im nächsten Schritt erfolgt eine Qualitätsprüfung der Eingangsdaten auf Vollständigkeit, Plausibilität, Konsistenz, Validität und Aktualität. Anschließend verarbeiten wir die Daten. Wir aggregieren die Datensätze, lösen synthetische Produktbundles auf, um dann die Daten in unser Hochrechnungsmodell zu überführen. In diesem Schritt passiert die wahre Magie, aber wie genau wir zu unserer Hochrechnung gelangen, bleibt Geschäftsgeheimnis.
Letzter Schritt nach finaler Prüfung ist der Datenrelease per Upload der Hochrechnung auf unsere Reportingplattform MO INSIGHTS. Die Rohdaten werden als Download, über SFTP und/oder per API-Schnittstelle bereitgestellt. Unsere Kunden erhalten Daten in höchster Qualität und Granularität.
Granularität und agile Marken-steuerung – eine Symbiose für den Erfolg
Wir möchten unseren Kunden mit einer exzellenten Datenqualität und exklusiven Insights eine transparente und effiziente Steuerung der Vertriebs- und Marketing-Aktivitäten ermöglichen. Die oben angesprochene Granularität der Daten ist von besonderer Bedeutung, wenn man die eigenen Brands agil im Versandhandel steuern möchte. Je tiefer die Insights, die Unternehmen über die Transaktionen erfahren, desto genauer können Marketing- und Vertriebsaktivitäten darauf ausgerichtet werden.
Für Unternehmen ist es elementar wichtig zu wissen, wie sich gesamte Kategorien, unter denen eigene Marken laufen, verhalten. Aber noch wertvoller ist das Wissen darüber, wie sich Verkäufe bis runter auf die einzelne PZN also auf das einzelne Produkt verhalten. Das kommt zum Beispiel bei Produktlaunches zum Tragen. Relevant in Bezug auf Granularität der Daten ist neben der Hierarchieebene auch der Zeitfaktor. In Bezug auf die Markensteuerung macht es einen eklatanten Unterschied, ob man Daten beispielsweise nur einmal im Jahr bezieht, oder im besten Fall sogar täglich (https://www.datamediq.com/tagesdaten-bei-datamediq/). Denkt man zum Beispiel an kostspielige TV–Kampagnen, dann ist es unerlässlich zu ermitteln, ob eine Maßnahme auch die gewünschten Effekte hatte und das Publikum zum Kauf angeregt wurde. Dafür reicht es einfach nicht aus Daten auf Monatsebene zu betrachten, sondern in diesem Beispiel ist ein tägliches Tracking der Daten zu empfehlen.
Auch auf dem Level der Regionalität haben hochgranulare Daten eine hohe Bedeutung. Es macht einen großen Unterschied, ob man Daten auf Basis einer bestimmten Region, eines bestimmten Landes oder sogar auf PLZ-Ebene bezieht. Es gibt Unternehmen, die mithilfe unserer Regionaldaten ihren Außendienst steuern. Viele Shopper tätigen den Erstkauf zwar in der stationären Apotheke und lassen sich dort auch ausführlich beraten. Aufgrund der Tatsache, dass die Preise im Versandhandel aber oft günstiger sind, wird der Nachkauf oft in der Online-Apotheke getätigt. Wenn man hier tiefgranulare Daten auf PLZ-Ebene bezieht, ist man in der Lage den Außendienst richtig einzuschätzen und die Leistung der Mitarbeiter zu tracken. Ein klarer Vorteil bei der Steuerung des Ressourceneinsatzes. Wir könnten noch viele weitere Beispiele anbringen, die die Relevanz datenbasierter Marken- und Vertriebssteuerung verdeutlichen würden.
Schauen Sie doch einfach dieses Webinar an, welches wir gemeinsam mit unserem Pricing-Partner buynomics zu diesem Thema veranstaltet haben.
Wenn Sie darüber hinaus mehr erfahren möchten, dann nehmen Sie Kontakt zu uns auf. Im Rahmen einer Erstberatung oder eines Demotermins zeigen wir Ihnen gerne Ihre Chancen im Pharma-Versandhandel auf. Buchen Sie jetzt einen Termin!